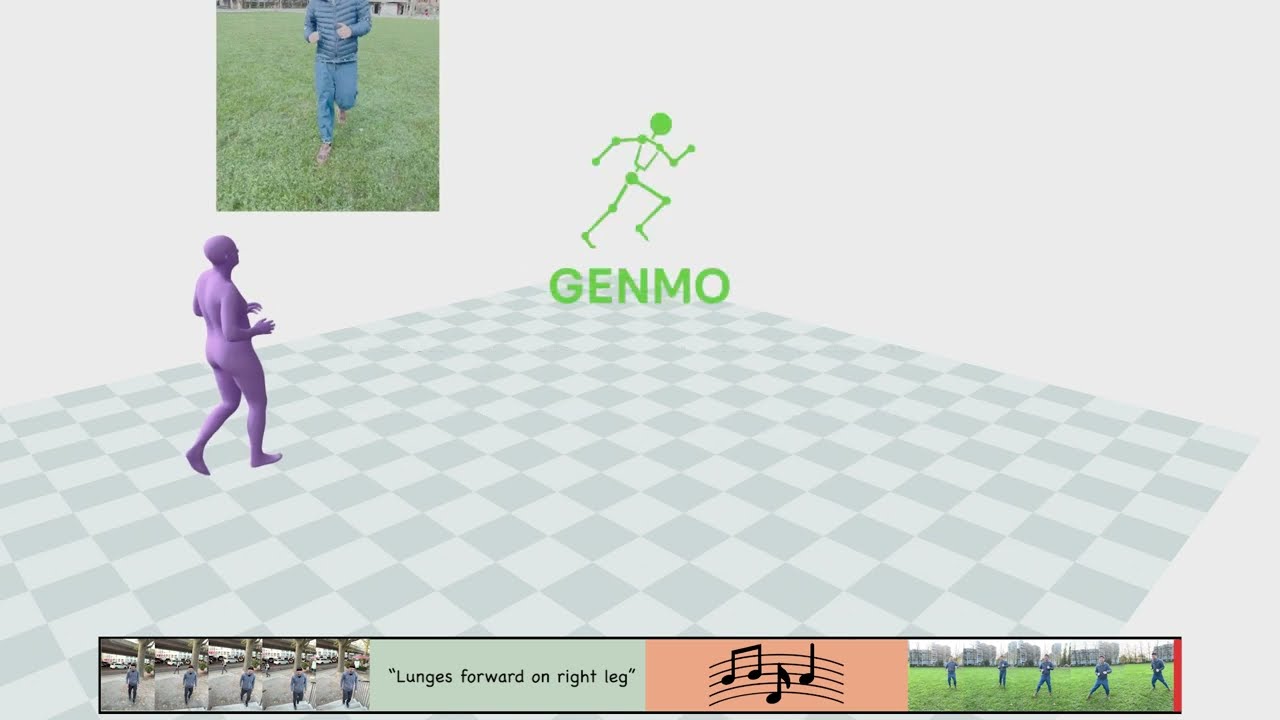
GENMO: il nuovo modello AI di NVIDIA che anima il corpo umano da testo, audio e video
Un unico modello per fare tutto: generazione e stima del movimento umano
Fino a oggi, nel mondo dell’intelligenza artificiale applicata al movimento umano, la regola era separare le funzioni: da una parte i modelli di motion generation, capaci di creare danze o movimenti da un prompt testuale o audio; dall’altra quelli di motion estimation, progettati per ricostruire il movimento a partire da video o sequenze keyframe. Due mondi distinti, con architetture dedicate, dataset specifici e compiti diversi.Con GENMO, NVIDIA sovverte questa logica e presenta un modello generalista che unisce entrambi gli approcci in un’unica architettura. Il risultato è un sistema capace sia di stimare il movimento globale del corpo da fonti come video o annotazioni 2D, sia di generare animazioni coerenti partendo da testo, musica, immagini, keyframe 3D o combinazioni di questi elementi.
Un approccio sinergico: regressione + diffusione
Il cuore di GENMO è l'idea che la motion estimation possa essere riformulata come una motion generation vincolata. In altre parole, stimare un movimento da un video significa generare un movimento che rispetti esattamente i vincoli imposti dall’osservazione (video, keypoint, ecc).Per farlo, il modello combina tecniche di regressione diretta con quelle di diffusione generativa, integrando dati da video in-the-wild con annotazioni 2D e descrizioni testuali. In questo modo, GENMO riesce a:
- Generare animazioni fluide da prompt testuali
- Ricostruire fedelmente movimenti da input reali
- Fondere più condizioni diverse (es. audio + video + testo)
Il training è guidato da un obiettivo ibrido che sfrutta entrambe le modalità, migliorando sia la qualità dell’estimazione che la diversità generativa.
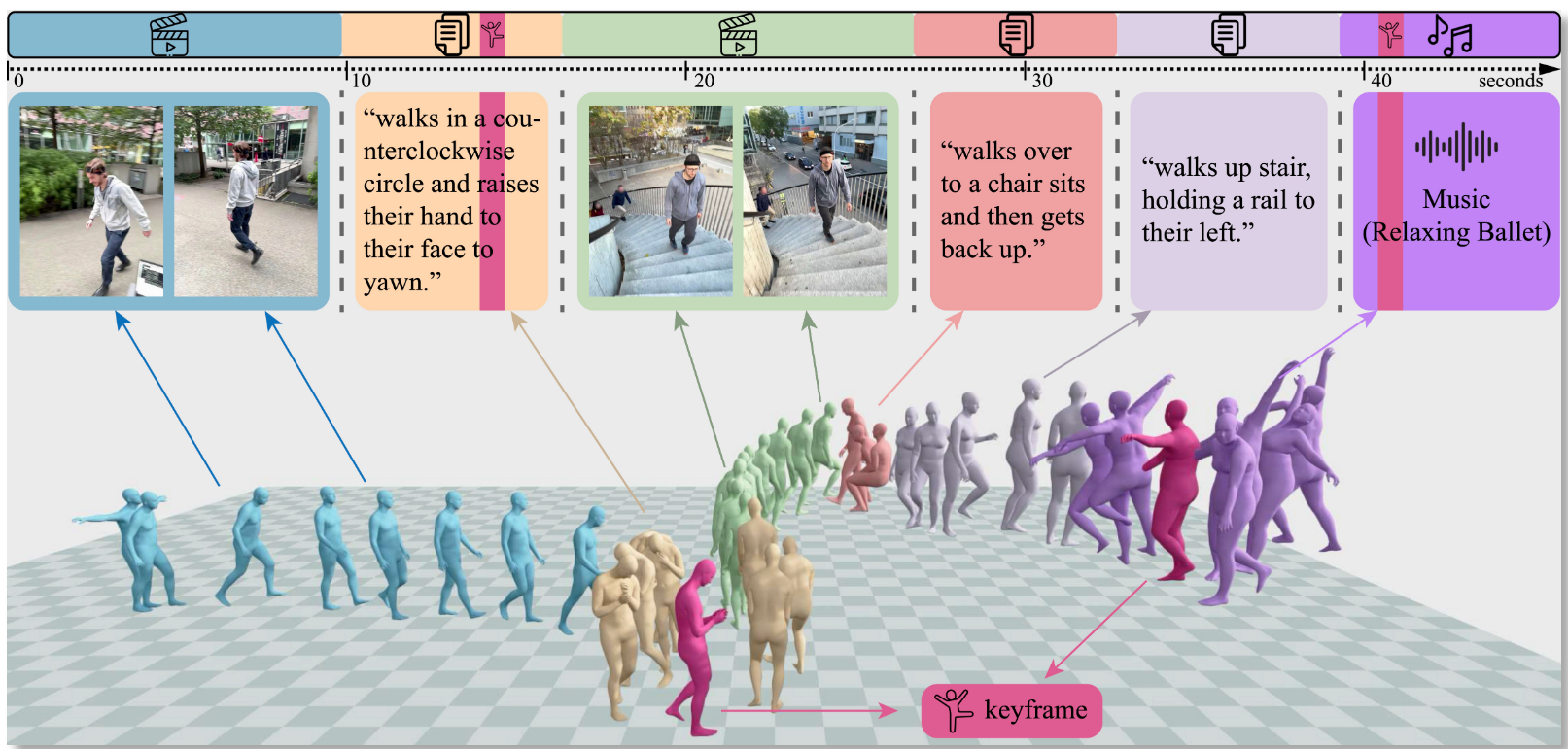
Motion generation da condizioni miste: testo, video, audio e 3D keyframes
GENMO brilla per flessibilità. Gli utenti possono fornire sequenze ibride come:
- Un video iniziale
- Una frase descrittiva centrale
- Una sequenza audio
- Un finale con keyframe 3D
Il modello genera un'unica animazione continua e coerente, anche in presenza di condizioni interrotte o eterogenee nel tempo. Il passaggio tra segmenti è fluido, e si può anche sostituire un input durante la generazione (es. cambiare la parte di testo, aggiornare un video di partenza).Esempi pratici:
- Una coreografia che parte da un video reale e si sviluppa seguendo un prompt testuale
- Una danza generata da una base musicale con aggiunta di movimenti specifici via 3D keyframe
- Una scena action che integra frame video con comandi descrittivi
Il tutto in un singolo forward pass, senza bisogno di post-processing.
Arbitrary-length motion e training su video reali
GENMO supporta la generazione di movimento arbitrario, ovvero senza limiti di durata predefiniti. Questo è reso possibile dalla sua architettura flessibile, che elabora in modo dinamico input lunghi e variabili nel tempo.Il training avviene anche su video reali in-the-wild con annotazioni 2D, cosa che consente al modello di:
- Gestire meglio condizioni complesse (es. occlusioni, pose incomplete)
- Migliorare la qualità del movimento stimato
- Aumentare la varietà e creatività delle sequenze generate
Il risultato è un modello che funziona sia in modalità controllata, sia in contesti non supervisionati.
Music-to-dance e interazione testuale
Una delle funzioni più impressionanti di GENMO è la generazione di danza da musica. Basta fornire un file audio (es. MP3 o stream), e il modello crea una sequenza di movimento che segue ritmo, beat e variazioni sonore.In alternativa, è possibile scrivere più prompt testuali per segmenti diversi:
- "Cammina lentamente" → "Si gira e alza il braccio" → "Inizia a correre con energia"
GENMO interpreterà ogni prompt in un segmento temporale definito, creando una motion continua con transizioni morbide. La possibilità di mescolare testo e audio lo rende uno dei modelli più creativi mai visti.
Chi può usare GENMO (e per cosa)
Attualmente, GENMO è un progetto di ricerca pubblicato da NVIDIA. Non ha ancora un'interfaccia pubblica via browser, ma è possibile accedere a video demo e paper su https://research.nvidia.com/labs/dair/genmo/.Gli ambiti di applicazione potenziali sono vastissimi:
- Videogiochi: animazioni realistiche da comandi vocali o script
- Cinema e VFX: previsualizzazioni rapide da audio o storyboard
- Avatar digitali: danza, espressioni corporee, performance
- VR/AR: movimenti coerenti in ambienti immersivi
- Ricerca: analisi di movimento umano su dati reali
Con il codice sorgente in arrivo, si prospetta una nuova ondata di tool che integreranno GENMO in pipeline creative, artistiche e scientifiche.
Link ufficiale: https://research.nvidia.com/labs/dair/genmo/
✨ Vuoi scoprire come usare modelli come GENMO per generare movimenti da musica, testo e video? Visita il canale YouTube AI Universo per demo e guide sull’AI nel mondo creativo!