AudioX: il modello AI che genera qualsiasi suono da qualsiasi input
Un salto evolutivo nell'audio generativo con AudioX
L’intelligenza artificiale sta rivoluzionando ogni forma di contenuto digitale — testi, immagini, video e ora anche audio.
Ed è qui che entra in scena AudioX, un nuovo modello AI sviluppato da un team di ricerca cinese che promette di generare audio di alta qualità a partire da qualsiasi tipo di input, da testo, immagini, video o altri suoni.AudioX è definito come un Diffusion Transformer, progettato per affrontare la sfida più difficile nel mondo dell'audio AI: la generazione cross-modale, ovvero la capacità di creare suoni realistici e coerenti partendo da dati di natura diversa.Che tu voglia generare una colonna sonora da un’immagine, creare effetti sonori per un video, oppure sintetizzare voci, strumenti e ambienti da uno script, AudioX sembra già essere uno dei tool più completi mai visti.
🎯 Scopri qui AudioX: il primo modello AI che trasforma testo, immagini, video o audio in suoni realistici di nuova generazione.
Come funziona AudioX: architettura e prestazioni
Alla base di AudioX c'è un'architettura ibrida che unisce:
- Diffusion Models → per la generazione progressiva dell'audio, frame per frame, mantenendo naturalezza e dettaglio
- Transformer → per comprendere ed elaborare input complessi come linguaggio, immagini e tracce audio
Questa combinazione consente ad AudioX di “immaginare” suoni con una precisione mai vista prima.Le sue capacità includono:
- Text-to-Audio → genera suoni da descrizioni (es. “una tempesta sulla spiaggia”)
- Image-to-Audio → crea effetti sonori da immagini statiche (es. una città notturna)
- Video-to-Audio → produce colonne sonore sincronizzate con scene mute
- Audio Editing & Extension → estende o modifica suoni esistenti con precisione millimetrica
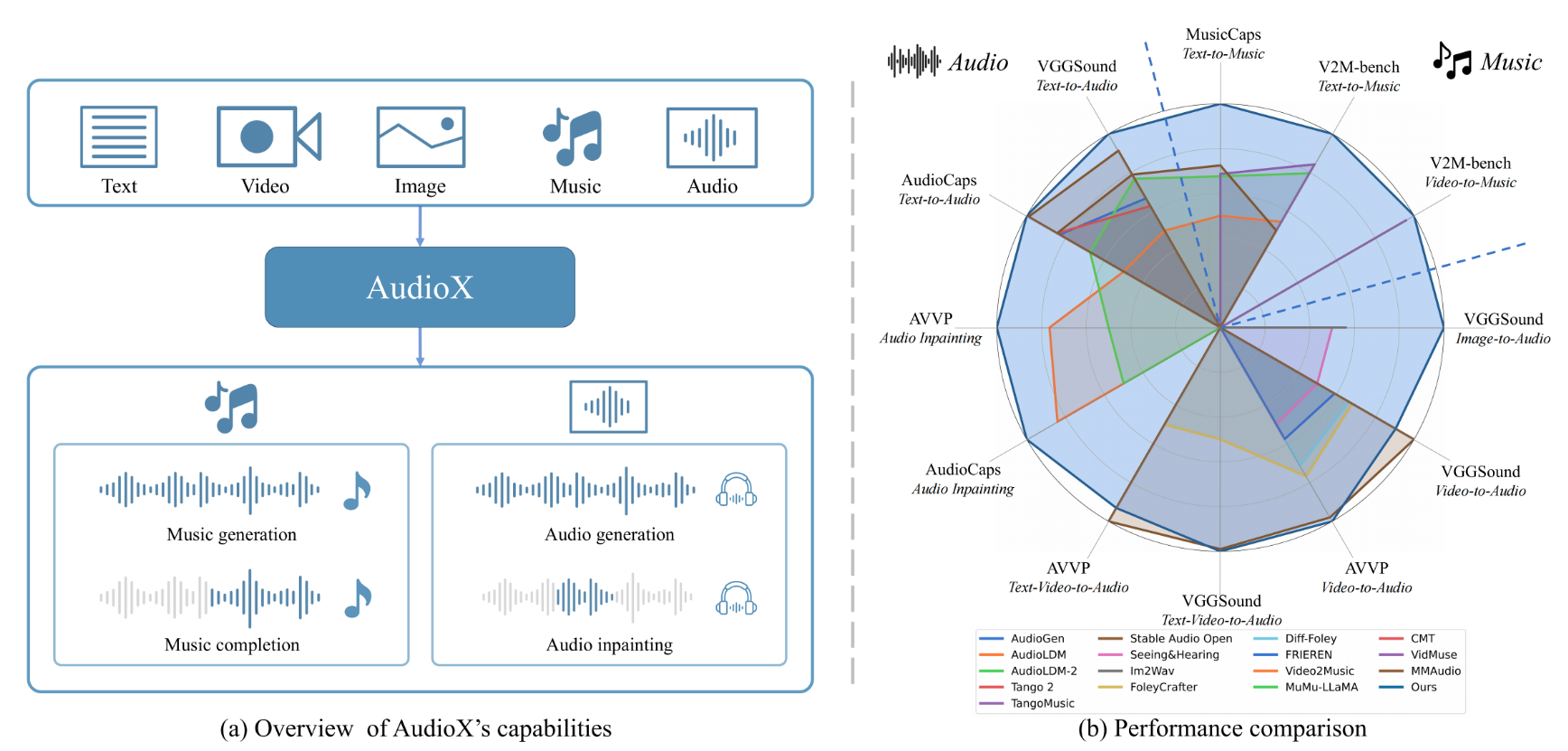
Le performance di AudioX sono state testate anche con metodi oggettivi come FAD (Fréchet Audio Distance) e MOS (Mean Opinion Score), superando modelli come MusicGen, AudioLDM 2 e TANGO nella maggior parte dei benchmark.
I casi d’uso: musica, film, VR e gaming
L’approccio “anything-to-audio” di AudioX apre scenari impensabili fino a pochi mesi fa.Ecco alcuni casi d’uso concreti:
- Produzione musicale → generare backing tracks, effetti e atmosfere da uno script
- Sound design per film → ottenere audio sincronizzato da storyboard o video muti
- Realtà virtuale e metaverso → creare ambienti sonori immersivi in tempo reale
- Gaming AI → generare effetti audio reattivi in base alle azioni del giocatore
- Educazione e accessibilità → trasformare contenuti visivi o testuali in esperienze audio guidate
Il team ha anche dimostrato che AudioX può mantenere la coerenza temporale, con suoni che evolvono seguendo logicamente l’input narrativo o visivo, una qualità fondamentale per la narrazione multimediale.
✨ Se vuoi scoprire tutti i migliori strumenti per creare contenuti AI, dai video agli effetti sonori, visita il nostro canale YouTube AI Universo per tutorial settimanali, test in tempo reale e guide pratiche!